

Almost everything you need to know about how pose estimation works
Pose estimation is a computer vision technique that predicts and tracks the location of a person or object. This is done by looking at a combination of the pose and the orientation of a given person/object.
But why would you want to detect and track a person’s or object’s location? And how does pose estimation actually work? What are the different approaches, what are its potential benefits and limitations, and how might you use it in your business?
In this guide, you’ll find answers to all of those questions and more. Whether you’re an experienced machine learning engineer considering implementation, a developer wanting to learn more, or a product manager looking to explore what’s possible with computer vision and pose estimation, this guide is for you.
Table of contents:
Part 1: Pose estimation – the basics
What is pose estimation?
Pose estimation is a computer vision task that infers the pose of a person or object in an mage or video. We can also think of pose estimation as the problem of determining the position and orientation of a camera relative to a given person or object.
This is typically done by identifying, locating, and tracking a number of keypoints on a given object or person. For objects, this could be corners or other significant features. And for humans, these keypoints represent major joints like an elbow or knee.
The goal of our machine learning models are to track these keypoints in images and videos.

Above: Tracking keypoints on a person playing ping pong.
Categories of pose estimation
When working with people, these keypoints represent major joints like elbows, knees, wrists, etc. This is referred to as human pose estimation.
Humans fall into a particular category of objects that are flexible. By bending our arms or legs, keypoints will be in different positions relative to others. Most inanimate objects are rigid. For instance, the corners of a brick are always the same distance apart regardless of the brick’s orientation. Predicting the position of these objects is known as rigid pose estimation.
There’s also a key distinction to be made between 2D and 3D pose estimation. 2D pose estimation simply estimates the location of keypoints in 2D space relative to an image or video frame. The model estimates an X and Y coordinate for each keypoint. 3D pose estimation works to transform an object in a 2D image into a 3D object by adding a z-dimension to the prediction.
3D pose estimation allows us to predict the actual spatial positioning of a depicted person or object. As you might expect, 3D pose estimation is a more challenging problem for machine learners, given the complexity required in creating datasets and algorithms that take into account a variety of factors – such as an image’s or video’s background scene, lighting conditions, and more.
Finally, there is a distinction between detecting one or multiple objects in an image or video. These two approaches can be referred to as single and multi pose estimation, and are largely self-explanatory: Single pose estimation approaches detect and track one person or object, while multi pose estimation approaches detect and track multiple people or objects.
Why does pose estimation matter?
With pose estimation, we’re able to track an object or person (or multiple people, as we’ll discuss shortly) in real-world space at an incredibly granular level. This powerful capability opens up a wide range of possible applications.
Pose estimation also differs from other common computer vision tasks in some important ways. A task like object detection also locates objects within an image. This localization, though, is typically coarse-grained, consisting of a bounding box encompassing the object. Pose estimation goes further, predicting the precise location of keypoints associated with the object.
We can clearly envision the power of pose estimation by considering its application in automatically tracking human movement. From virtual sports coaches and AI-powered personal trainers to tracking movements on factory floors to ensure worker safety, pose estimation has the potential to create a new wave of automated tools designed to measure the precision of human movement.
In addition to tracking human movement and activity, pose estimation opens up applications in a range of areas, such as:
- Augmented reality
- Animation
- Gaming
- Robotics
Of course, this isn’t an exhaustive list, but it includes some of the primary ways in which pose estimation is shaping our future.
Part 2: How does pose estimation work?
Now that we know a bit about what pose estimation is, the distinctions between different types of pose estimation, and what it can be used for, let’s explore how it actually works in more depth.
We’ll look at several machine learning-based approaches to pose estimation and assess their advantages and limitations, focusing primarily on neural networks, which have become the state-of-the-art methods for pose estimation.
Primary techniques for pose estimation
In general, deep learning architectures suitable for pose estimation are based on variations of convolutional neural networks (CNNs). For a gentle introduction, check out this guide to convolutional neural networks.
There are two overarching approaches: a bottom-up approach, and a top-down approach.
With a bottom-up approach, the model detects every instance of a particular keypoint (e.g. all left hands) in a given image and then attempts to assemble groups of keypoints into skeletons for distinct objects.
A top-down approach is the inverse – the network first uses an object detector to draw a box around each instance of an object, and then estimates the keypoints within each cropped region.
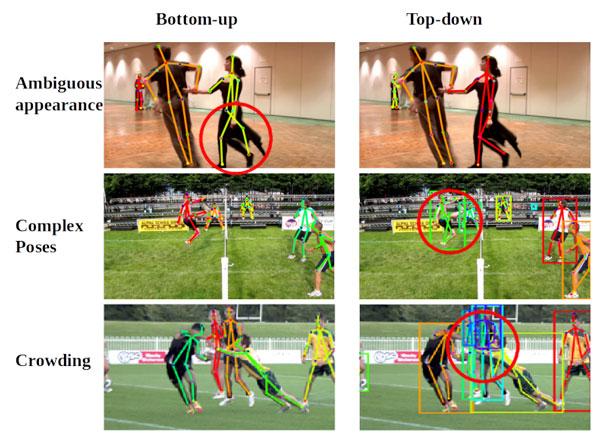
Above: Comparing bottom-up and top-down approaches
And though we referenced this previously, it’s important to remember the distinction between 2D pose estimation and 3D pose estimation. The two tasks carry different data requirements, produce different outputs (2D pixel values vs a 3D spatial arrangement), and are generally used to solve different problems.
Basic structure
Deep learning models for pose estimation come in a few varieties related to the top-down and bottom-up approaches discussed above. Most begin with an encoder that accepts an image as input and extracts features using a series of narrowing convolution blocks. What comes after the encoder depends on the method of pose estimation.
The most conceptually simple method uses a regressor to output final predictions of each keypoint location. The resulting model accepts an image as input and outputs X, Y, and potentially Z coordinates for each keypoint you’re trying to predict. In practice, however, this architecture does not produce accurate results without additional refinement.
A slightly more complicated approach uses an encoder-decoder architecture. Instead of estimating keypoint coordinates directly, the encoder is fed into a decoder, which creates heatmaps representing the likelihood that a keypoint is found in a given region of an image.
During post-processing, the exact coordinates of a keypoint are found by selecting heatmap locations with the highest keypoint likelihood. In the case of multi-pose estimation, a heatmap may contain multiple areas of high keypoint likelihood (e.g. multiple right hands in an image). In these cases, additional post-processing is required to assign each area to a specific object instance.
Top-down approaches also use an encoder-decoder architecture to output heatmaps, but they contain an additional step. An object detection module is placed between the encoder and decoder and is used to crop regions of an image likely to contain an object.
Keypoint heatmaps are then predicted individually for each box. Rather than having a single heatmap containing the likely location of all left hands in an image, we get a series of bounding boxes that should only contain a single keypoint of each type. This approach makes it easy to assign keypoints to specific instances without a lot of post-processing.
Both types of architectures discussed thus far apply equally to 2D and 3D pose estimation. There are, however, a few options worth mentioning that are specific to 3D rigid pose estimation.
Rather than predicting the coordinates of each keypoint in [X, Y, Z] space, it’s instead possible to predict the 6 degrees of freedom of an object and apply the transformation to a reference skeleton. For example, instead of trying to predict the 3D position of the top of a water bottle, you would instead predict the 3D coordinates of it’s center of mass and then predict the rotation of the bottle in an image relative to a reference coordinate system.
This method of prediction is particularly useful for applications in AR, VR, or other apps that use 3D rendering software like Unity. It can, however, be hard to train accurate models.
Model architecture overview
There are too many specific neural network architectures to cover them all here, but there we’ll highlight a few robust, reliable ones that make good places to start.
Stacked-Hourglass networks, Mask-RCNN, and other encoder-decoder networks
Pure encoder-decoder networks take an image as input and output heatmaps for each keypoint. They are a good place to start if you’re new to neural pose estimation. If you need to detect multiple poses, Mask-RCNN is a versatile architecture that predicts bounding boxes for objects in an image and then predicts poses within the regions of the image enclosed in the box.
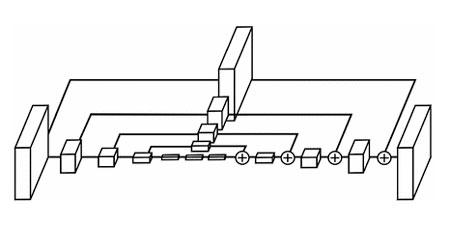
Above: Stacked Hourglass Networks for Human Pose Estimation
PersonLab / PoseNet and OpenPose
OpenPose and PersonLab (also known as PoseNet) are variants of an encoder-decoder architecture with a twist. In addition to outputting heatmaps, the model also outputs refinements to heatmaps in the form of short, mid, and long-range offsets. Heatmaps identify broad regions of an image where a keypoint is likely to be found, while offsets guide out predictions within a region to a more accurate final prediction. More on the PoseNet architecture developed by Google and its post-processing can be found here.
Convolutional Pose Machines
Convolutional pose machines build on the encoder-decoder architecture by iteratively refining heatmap predictions using additional network layers and feature extraction. The final output is a single set of heatmaps, and post-processing involves identifying the pixels at which the heatmap probability is the highest for each keypoint.
How pose estimation works on the edge
If your use case requires that pose estimation work in real-time, without internet connectivity, or on private data, you might be considering running your pose estimation model directly on an edge device like a mobile phone or IoT board.
In those cases, you’ll need to choose specific model architectures to make sure everything runs smoothly on these lower power devices. Here are a few tips and tricks to ensure your models are ready for edge deployment:
- Use MobileNet-based architectures for your encoder. This architecture makes use of layer types like depthwise separable convolutions that require fewer parameters and less computation while still providing solid accuracy.
- Add a width multiplier to your model so you can adjust the number of parameters in your network to meet your computation and memory constraints. The number of filters in a convolution layer, for example, greatly impacts the overall size of your model. Many papers and open-source implementations will treat this number as a fixed constant, but most of these models were never intended for mobile or edge use. Adding a parameter that multiplies the base number of filters by a constant fraction allows you to modulate the model architecture to fit the constraints of your device. For some tasks, you can create much, much smaller networks that perform just as well as large ones.
- Shrink models with quantization, but beware of accuracy drops. Quantizing model weights can save a bunch of space, often reducing the size of a model by a factor of 4 or more. However, accuracy will suffer. Make sure you test quantized models rigorously to determine if they meet your needs.
- Input and output sizes can be smaller than you think! If you’re designing a coaching app, it’s tempting to think that your pose estimation model needs to be able to accept full resolution video frames as an input. In most cases, edge devices won’t have nearly enough processing power to handle this. Instead, it’s common to train pose estimation models to take images as small as 224×224 pixels.
Part 3: Use cases and applications
In this section, we’ll provide an overview of real-world use cases for pose estimation. We’ve mentioned several of them in previous sections, but here we’ll dive a bit deeper and explore the impact this computer vision technique can have across industries.
Specifically, we’ll examine how pose estimation is used in the following areas:
- Human activity and movement
- Augmented reality experiences
- Animation & Gaming
- Robotics
Human activity and movement
One of the most clear areas in which pose estimation is applicable is in tracking and measuring human movement. But tracking movement in and of itself isn’t something you can put into production, generally speaking. With a little creative thinking, however, the applications resulting from tracking this movement are dynamic and far-reaching.
Consider, as one example, an AI-powered personal trainer that works simply by pointing a camera at a person completing a workout, and having a human pose estimation model (trained on a number specific poses related to a workout regimen) indicate whether or not a given exercise has been completed properly.
This kind of application could enable safer and more inspirational home workout routines, while also increasing the accessibility and decreasing the costs associated with professional physical trainers.
And given that pose estimation models can now run on mobile devices and without internet access, this kind of application could easily extend the access of this kind of expertise to remote or otherwise hard-to-reach places.
Using human pose estimation to track human movement could also power a number of other experiences, including but not limited to:
- AI-powered sports coaches
- Workplace activity monitoring
- Crowd counting and tracking (e.g. for retail outlets measuring foot traffic)
Augmented reality experiences
While not immediately evident, pose estimation also presents an opportunity to create more realistic and responsive augmented reality (AR) experiences.
For much of this guide, we’ve focused on human pose estimation. But if you’ll recall from part 1 of this guide, we can also locate and track objects with non-variable keypoints. From pieces of paper, to musical instruments, to…well, pretty much anything you can think of, rigid pose estimation allows us to determine a given object’s primary keypoints and track them as they move through real-world spaces.
How does this relate to AR? Well AR, in its essence, allows us to place digital objects in real-world scenes. This could be testing out a piece of furniture in your living room by placing a 3D rendering of it in the space, or trying on a pair of digitally-rendered shoes.
So where does pose estimation enter the picture? If we’re able to locate and accurately track a physical object in real-world space, then we can also overlay a digital AR object onto the real object that’s being tracked.
Animation & Gaming
Traditionally, character animation has been a manual process that’s relied on bulky and expensive motion capture systems. However, with the advent of deep learning approaches to pose estimation, there’s the distinct potential that these systems can be streamlined and in many ways automated.
Recent advances in both pose estimation and motion capture technology are making this shift possible, allowing for character animation that doesn’t rely on markers or specialized suits, while still being able to capture motion in real-time.
Similarly, capturing animations for immersive video game experiences can also potentially be automated by deep learning-based pose estimation. This kind of gaming experience was popularized with Microsoft’s Kinect depth camera, and advances in gesture recognition promise to fulfill the real-time requirement that these systems demand.
Robotics
Traditionally, industrial robotics have employed 2D vision systems to enable robots to perform their various tasks. However, this 2D approach presents a number of limitations. Namely, computing the position to which a robot should move, given this 2D representation of space, requires intensive calibration processes, and become inflexible to environmental changes unless reprogrammed.
With the advent of 3D pose estimation, however, the opportunity exists to create more responsive, flexible, and accurate robotics systems.
For a more detailed look at the potential of pose estimation in tackling salient problems in robotics, check out this research paper from the Technical University of Denmark.
Part 4: Resources
We hope the above overview was helpful in understanding the basics of pose estimation and how it can be used in the real world. But with all things, more answers lead to more questions.
This final section will provide a series of organized resources to help you take the next step in learning all there is to know about pose estimation.
In the interest of keeping this list relatively accessible, we’ve curated our top resources for each of the following areas:
- Getting Started
- Tutorials
- Literature Review
- Available Datasets
Getting Started
- An Overview of Human Pose Estimation with Deep Learning
- A Guide to Human Pose Estimation with Deep Learning
- Wikipedia entry for Pose Estimation
- [GitHub] awesome-human-pose-estimation: A collection of resources in Human Pose estimation
Tutorials
- Pose Estimation on iOS
- Pose Estimation on Android
- Deep Learning based Human Pose Estimation using OpenCV
Literature Review
Available datasets
Finding and using training data for pose estimation is a bit tricky, given its different flavors and the fact that we can predict in both 2 and 3 dimensions. As such, when attempting to implement pose estimation in an application, it’s important to understand what’s included in each dataset, as well as what the task at hand requires.
Here’s a look at some popular datasets for both 3D and 2D pose estimation:
For 3D Pose Estimation
- DensePose
- UP-3D
- Human3.6m
- 3D Poses in the Wild
- HumanEva
- Total Capture
- SURREAL (Synthetic hUmans foR REAL tasks)
- JTA Dataset
- MPI-INF-3DHP
For 2D Pose Estimation
- MPII Human Pose Dataset
- Leeds Sports Pose
- Frames Labeled in Cinema
- Frames Labeled in Cinema Plus
- YouTube Pose (VGG)
- BBC Pose (VGG)
- COCO Keypoints
Pose Estimation on Mobile
The benefits of using pose estimation aren’t limited to applications that run on servers or in the cloud.
In fact, pose estimation models can be made small and fast enough to run directly on mobile devices, opening up a wide range of possibilities: AI-powered sports coaches and personal trainers, highly-realistic and immersive AR experiences, and crowd counting/tracking, to name a few.
From brand loyalty, to user engagement and retention, and beyond, implementing pose estimation on-device has the potential to delight users in new and lasting ways, all while reducing cloud costs and keeping user data private.
Fritz AI is the machine learning platform that makes it easy to teach devices how to see, hear, sense, and think. To learn more about how Fritz AI can help you build AI-powered, immersive AR experiences.
Comments 0 Responses