Almost everything you need to know about how object detection works.
Object detection is a computer vision technique that allows us to identify and locate objects in an image or video. With this kind of identification and localization, object detection can be used to count objects in a scene and determine and track their precise locations, all while accurately labeling them.
Imagine, for example, an image that contains two cats and a person. Object detection allows us to at once classify the types of things found while also locating instances of them within the image.

In this guide, you’ll find answers to all of those questions and more. Whether you’re an experienced machine learning engineer considering implementation, a developer wanting to learn more, or a product manager looking to explore what’s possible with computer vision and object detection, this guide is for you.
But how does object detection actually work? What are the different approaches, what are its potential benefits and limitations, and how might you use it in your business?
Here’s a look at what we’ll cover:
Table of Contents
Part 1: Object detection – the basics
What is object detection?
Object detection is a computer vision technique that works to identify and locate objects within an image or video. Specifically, object detection draws bounding boxes around these detected objects, which allow us to locate where said objects are in (or how they move through) a given scene.
Object detection is commonly confused with image recognition, so before we proceed, it’s important that we clarify the distinctions between them.
Image recognition assigns a label to an image. A picture of a dog receives the label “dog”. A picture of two dogs, still receives the label “dog”.
Object detection, on the other hand, draws a box around each dog and labels the box “dog”. The model predicts where each object is and what label should be applied. In that way, object detection provides more information about an image than recognition.
Here’s an example of how this distinction looks in practice:

Modes and types of object detection
Broadly speaking, object detection can be broken down into machine learning-based approaches and deep learning-based approaches.
In more traditional ML-based approaches, computer vision techniques are used to look at various features of an image, such as the color histogram or edges, to identify groups of pixels that may belong to an object. These features are then fed into a regression model that predicts the location of the object along with its label.
On the other hand, deep learning-based approaches employ convolutional neural networks (CNNs) to perform end-to-end, unsupervised object detection, in which features don’t need to be defined and extracted separately. For a gentle introduction to CNNs, check out this overview.
Because deep learning methods have become the state-of-the-art approaches to object detection, these are the techniques we’ll be focusing on for the purposes of this guide.
Why is object detection important?
Object detection is inextricably linked to other similar computer vision techniques like image recognition and image segmentation, in that it helps us understand and analyze scenes in images or video.
But there are important differences. Image recognition only outputs a class label for an identified object, and image segmentation creates a pixel-level understanding of a scene’s elements. What separates object detection from these other tasks is its unique ability to locate objects within an image or video. This then allows us to count and then track those objects.
Given these key distinctions and object detection’s unique capabilities, we can see how it can be applied in a number of ways:
- Crowd counting
- Self-driving cars
- Video surveillance
- Face detection
- Anomaly detection
Of course, this isn’t an exhaustive list, but it includes some of the primary ways in which object detection is shaping our future.
Part 2: How does object detection work?
Now that we know a bit about what object detection is, the distinctions between different types of object detection, and what it can be used for, let’s explore in more depth how it actually works.
In this section, we’ll look at several deep learning-based approaches to object detection and assess their advantages and limitations.
Just as a reminder—for the purposes of this overview, we’re going to look at the approaches that use neural networks, which have become the state-of-the-art methods for object detection.
In this section, we’ll look at several deep learning-based approaches to object detection and assess their advantages and limitations. Just as a reminder—for the purposes of this overview, we’re going to look at the approaches that use neural networks, which have become the state-of-the-art methods for object detection.
Basic structure
Deep learning-based object detection models typically have two parts. An encoder takes an image as input and runs it through a series of blocks and layers that learn to extract statistical features used to locate and label objects.
Outputs from the encoder are then passed to a decoder, which predicts bounding boxes and labels for each object.
The simplest decoder is a pure regressor. The regressor is connected to the output of the encoder and predicts the location and size of each bounding box directly. The output of the model is the X, Y coordinate pair for the object and its extent in the image.
Though simple, this type of model is limited. You need to specify the number of boxes ahead of time. If your image has two dogs, but your model was only designed to detect a single object, one will go unlabeled. However, if you know the number of objects you need to predict in each image ahead of time, pure regressor-based models may be a good option.
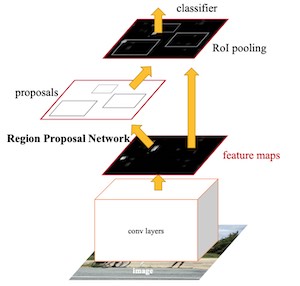
An extension of the regressor approach is a region proposal network. In this decoder, the model proposes regions of an image where it believes an object might reside. The pixels belonging to these regions are then fed into a classification subnetwork to determine a label (or reject the proposal).
It then runs the pixels containing those regions through a classification network. The benefit of this method is a more accurate, flexible model that can propose arbitrary numbers of regions that may contain a bounding box. The added accuracy, though, comes at the cost of computational efficiency.
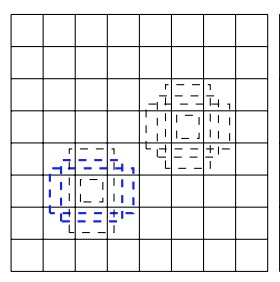
Single shot detectors (SSDs) seek a middle ground. Rather than using a subnetwork to propose regions, SSDs rely on a set of predetermined regions. A grid of anchor points is laid over the input image, and at each anchor point, boxes of multiple shapes and sizes serve as regions.
For each box at each anchor point, the model outputs a prediction of whether or not an object exists within the region and modifications to the box’s location and size to make it fit the object more closely.
Because there are multiple boxes at each anchor point and anchor points may be close together, SSDs produce many potential detections that overlap.
Post-processing must be applied to SSD outputs in order to prune away most of these predictions and pick the best one. The most popular post-processing technique is known as non-maximum suppression.
Finally, a note on accuracy. Object detectors output the location and label for each object, but how do we know how well the model is doing? For an object’s location, the most commonly-used metric is intersection-over-union (IOU). Given two bounding boxes, we compute the area of the intersection and divide by the area of the union. This value ranges from 0 (no interaction) to 1 (perfectly overlapping). For labels, a simple “percent correct” can be used.
Model architecture overview
R-CNN, Faster R-CNN, Mask R-CNN
A number of popular object detection models belong to the R-CNN family. Short for region convolutional neural network, these architectures are based on the region proposal structure discussed above. Over the years, they’ve become both more accurate and more computationally efficient. Mask R-CNN is the latest iteration, developed by researchers at Facebook, and it makes a good starting point for server-side object detection models.
YOLO, MobileNet + SSD, SqueezeDet
There are also a number of models that belong to the single shot detector family. The main difference between these variants are their encoders and the specific configuration of predetermined anchors. MobileNet + SSD models feature a MobileNet-based encoder, SqueezeDet borrows the SqueezeNet encoder, and the YOLO model features its own convolutional architecture. SSDs make great choices for models destined for mobile or embedded devices.
CenterNet
More recently, researchers have developed object detection models that do away with the need for region proposals entirely. CenterNet treats objects as single points, predicting the X, Y coordinates of an object’s center and its extent (height and width). This technique has proven both more efficient and accurate than SSD or R-CNN approaches.
How object detection works on the edge
If your use case requires that object detection work in real-time, without internet connectivity, or on private data, you might be considering running your object detection model directly on an edge device like a mobile phone or IoT board.
In those cases, you’ll need to choose specific model architectures to make sure everything runs smoothly on these lower power devices. Here are a few tips and tricks to ensure your models are ready for edge deployment:
- Prune your network to include fewer convolution blocks. Most papers use network architectures that are not constrained by compute or memory resources. This leads to networks with far more layers and parameters than are required to generate acceptable predictions.
- Add a width multiplier to your model so you can adjust the number of parameters in your network to meet your computation and memory constraints. The number of filters in a convolution layer, for example, greatly impacts the overall size of your model. Many papers and open-source implementations will treat this number as a fixed constant, but most of these models were never intended for mobile use. Adding a parameter that multiplies the base number of filters by a constant fraction allows you to modulate the model architecture to fit the constraints of your device. For some tasks, you can create much, much smaller networks that perform just as well as large ones.
- Shrink models with quantization, but beware of accuracy drops. Quantizing model weights can save a bunch of space, often reducing the size of a model by a factor of 4 or more. However, accuracy will suffer. Make sure you test quantized models rigorously to determine if they meet your needs.
- Input and output sizes can be smaller than you think! If you’re designing a photo organization app, it’s tempting to think that your object detection model needs to be able to accept full resolution photos as an input. In most cases, edge devices won’t have nearly enough processing power to handle this. Instead, it’s common to train object detection models at modest resolutions, then downscale input images at runtime.
To see just how small you can make these networks with good results, check out this post on creating a tiny object detection model for mobile devices.
Part 3: Use cases and applications
In this section, we’ll provide an overview of real-world use cases for object detection. We’ve mentioned several of them in previous sections, but here we’ll dive a bit deeper and explore the impact this computer vision technique can have across industries.
Specifically, we’ll examine how object detection can be used in the following areas:
- Video surveillance
- Crowd counting
- Anomaly detection (i.e. in industries like agriculture, health care)
- Self-driving cars
Video surveillance
Because state-of-the-art object detection techniques can accurately identify and track multiple instances of a given object in a scene, these techniques naturally lend themselves to automating video surveillance systems.
For instance, object detection models are capable of tracking multiple people at once, in real-time, as they move through a given scene or across video frames. From retail stores to industrial factory floors, this kind of granular tracking could provide invaluable insights into security, worker performance and safety, retail foot traffic, and more.
Crowd counting
Crowd counting is another valuable application of object detection. For densely populated areas like theme parks, malls, and city squares, object detection can help businesses and municipalities more effectively measure different kinds of traffic—whether on foot, in vehicles, or otherwise.
This ability to localize and track people as they maneuver through various spaces could help businesses optimize anything from logistics pipelines and inventory management, to store hours, to shift scheduling, and more. Similarly, object detection could help cities plan events, dedicate municipal resources, etc.
Anomaly detection
Anomaly detection is a use case of object detection that’s best explained through specific industry examples.
In agriculture, for instance, a custom object detection model could accurately identify and locate potential instances of plant disease, allowing farmers to detect threats to their crop yields that would otherwise not be discernible to the naked human eye.
And in health care, object detection could be used to help treat conditions that have specific and unique symptomatic lesions. One such example of this comes in the form of skin care and the treatment of acne—an object detection model could locate and identify instances of acne in seconds.
What’s particularly important and compelling about these potential use cases is how they leverage and provide knowledge and information that’s generally only available to agricultural experts or doctors, respectively.
Self-driving cars
Real-time car detection models are key to the success of autonomous vehicle systems. These systems need to be able to identify, locate, and track objects around them in order to move through the world safely and efficiently.
And while tasks like image segmentation can be (and often are) applied to autonomous vehicles, object detection remains a foundational task that underpins current work on making self-driving cars a reality.
Part 4: Resources for object detection
We hope the above overview was helpful in understanding the basics of object detection and how it can be used in the real world. But with all things, more answers lead to more questions.
This final section will provide a series of organized resources to help you take the next step in learning all there is to know about object detection.
In the interest of keeping this list relatively accessible, we’ve curated our top resources for each of the following areas:
- Getting started
- Tutorials
- Literature review
- Available datasets
Getting started
- A Beginner’s Guide to Object Detection
- What Is Object Detection?
- Classification vs Detection vs Segmentation Models: The Differences Between Them and When to Use Each
Tutorials
- Detecting objects in videos and camera feeds using Keras, OpenCV, and ImageAI
- Basics of Image Classification with PyTorch
- Object Detection with 10 lines of code
- A Gentle Guide to Deep Learning Object Detection
Literature review
- Papers with Code: Object Detection
- [GitHub] amusi/awesome-object-detection
- Beginner’s Guide to Object Detection Algorithms
Datasets available
Object Detection on Mobile
The benefits of using object detection aren’t limited to applications that run on servers or in the cloud.
In fact, object detection models can be made small and fast enough to run directly on mobile and edge devices, opening up a range of possibilities, including applications for real-time video surveillance, crowd counting, anomaly detection, and more.
From brand loyalty, to user engagement and retention, and beyond, implementing object detection on-device has the potential to delight users in new and lasting ways, all while reducing cloud costs and keeping user data private.